Статистические техники криптоанализа
Содержание:
Стандартные шифры
ROT1
Этот шифр известен многим детям. Ключ прост: каждая буква заменяется на следующую за ней в алфавите. Так, А заменяется на Б, Б — на В, и т. д. Фраза «Уйрйшоьк Рспдсбннйту» — это «Типичный Программист».
Попробуйте расшифровать сообщение:
Шифр транспонирования
В транспозиционном шифре буквы переставляются по заранее определённому правилу. Например, если каждое слово пишется задом наперед, то из hello world получается dlrow olleh. Другой пример — менять местами каждые две буквы. Таким образом, предыдущее сообщение станет eh ll wo ro dl.
Ещё можно использовать столбчатый шифр транспонирования, в котором каждый символ написан горизонтально с заданной шириной алфавита, а шифр создаётся из символов по вертикали. Пример:
Из этого способа мы получим шифр holewdlo lr. А вот столбчатая транспозиция, реализованная программно:
Азбука Морзе
В азбуке Морзе каждая буква алфавита, цифры и наиболее важные знаки препинания имеют свой код, состоящий из череды коротких и длинных сигналов:Чаще всего это шифрование передаётся световыми или звуковыми сигналами.
Сможете расшифровать сообщение, используя картинку?
Шифр Цезаря
Это не один шифр, а целых 26, использующих один принцип. Так, ROT1 — лишь один из вариантов шифра Цезаря. Получателю нужно просто сообщить, какой шаг использовался при шифровании: если ROT2, тогда А заменяется на В, Б на Г и т. д.
А здесь использован шифр Цезаря с шагом 5:
Моноалфавитная замена
Коды и шифры также делятся на подгруппы. Например, ROT1, азбука Морзе, шифр Цезаря относятся к моноалфавитной замене: каждая буква заменяется на одну и только одну букву или символ. Такие шифры очень легко расшифровываются с помощью частотного анализа.
Например, наиболее часто встречающаяся буква в английском алфавите — «E». Таким образом, в тексте, зашифрованном моноалфавитным шрифтом, наиболее часто встречающейся буквой будет буква, соответствующая «E». Вторая наиболее часто встречающаяся буква — это «T», а третья — «А».
Однако этот принцип работает только для длинных сообщений. Короткие просто не содержат в себе достаточно слов.
Шифр Виженера
Представим, что есть таблица по типу той, что на картинке, и ключевое слово «CHAIR». Шифр Виженера использует принцип шифра Цезаря, только каждая буква меняется в соответствии с кодовым словом.
В нашем случае первая буква послания будет зашифрована согласно шифровальному алфавиту для первой буквы кодового слова «С», вторая буква — для «H», etc. Если послание длиннее кодового слова, то для (k*n+1)-ой буквы, где n — длина кодового слова, вновь будет использован алфавит для первой буквы кодового слова.
Чтобы расшифровать шифр Виженера, для начала угадывают длину кодового слова и применяют частотный анализ к каждой n-ной букве послания.
Попробуйте расшифровать эту фразу самостоятельно:
Подсказка длина кодового слова — 4.
Шифр Энигмы
Энигма — это машина, которая использовалась нацистами во времена Второй Мировой для шифрования сообщений.
Есть несколько колёс и клавиатура. На экране оператору показывалась буква, которой шифровалась соответствующая буква на клавиатуре. То, какой будет зашифрованная буква, зависело от начальной конфигурации колес.
Существовало более ста триллионов возможных комбинаций колёс, и со временем набора текста колеса сдвигались сами, так что шифр менялся на протяжении всего сообщения.
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox. При правильном отображении в разделе «Вид» ищите кодировку. Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
- Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.
История и использование
Шифр Цезаря назван в честь Юлия Цезаря , который использовал алфавит, в котором расшифровка сдвигала три буквы влево.
Шифр Цезаря назван в честь Юлия Цезаря , который, согласно Светонию , использовал его со сдвигом на три (A становится D при шифровании, а D становится A при дешифровании) для защиты сообщений, имеющих военное значение. Хотя Цезарь был первым зарегистрированным применением этой схемы, известно, что другие шифры подстановки использовались и раньше.
Его племянник, Август , также использовал шифр, но со сдвигом вправо на единицу, и он не переходил в начало алфавита:
Существуют свидетельства того, что Юлий Цезарь также использовал более сложные системы, и один писатель, Авл Геллий , ссылается на (ныне утерянный) трактат о своих шифрах:
Неизвестно, насколько эффективным был шифр Цезаря в то время, но он, вероятно, был достаточно надежным, не в последнюю очередь потому, что большинство врагов Цезаря были неграмотными, а другие предположили, что сообщения были написаны на неизвестном иностранном языке. В то время нет никаких записей о каких-либо методах решения простых подстановочных шифров. Самые ранние сохранившиеся записи относятся к работам Аль-Кинди 9-го века в арабском мире с открытием частотного анализа .
Шифр Цезаря со сдвигом на единицу используется на обратной стороне мезузы для шифрования имен Бога . Это может быть пережитком более ранних времен, когда евреям не разрешалось есть мезузот. Сами буквы криптограммы содержат религиозно значимое «божественное имя», которое, согласно православной вере, сдерживает силы зла.
В 19 веке раздел личной рекламы в газетах иногда использовался для обмена сообщениями, зашифрованными с использованием простых схем шифрования. Кан (1967) описывает случаи, когда любовники участвовали в секретных сообщениях, зашифрованных с помощью шифра Цезаря в The Times . Даже в 1915 году шифр Цезаря использовался: русская армия использовала его как замену более сложным шифрам, которые оказались слишком трудными для освоения их войсками; Немецким и австрийским криптоаналитикам не составило труда расшифровать свои сообщения.
Конструкция из двух вращающихся дисков с шифром Цезаря может использоваться для шифрования или дешифрования кода.
Шифры Цезаря сегодня можно найти в детских игрушках, таких как секретные кольца-декодеры . Сдвиг Цезаря на тринадцать также выполняется в алгоритме ROT13 , простом методе обфускации текста, широко распространенном в Usenet и используемом для затемнения текста (например, анекдотов и спойлеров рассказов ), но серьезно не используемого в качестве метода шифрования.
В шифре Виженера используется шифр Цезаря с различным сдвигом в каждой позиции текста; значение сдвига определяется с помощью повторяющегося ключевого слова. Если длина ключевого слова равна длине сообщения, оно выбрано случайным образом , никогда не становится известно никому и никогда не используется повторно, это одноразовый блокнотный шифр, который доказал свою нерушимость. Условия настолько трудны, что на практике они никогда не достигаются. Ключевые слова короче сообщения (например, « », использовавшаяся Конфедерацией во время Гражданской войны в США ), вводят циклический паттерн, который может быть обнаружен с помощью статистически продвинутой версии частотного анализа.
В апреле 2006 года беглый босс мафии Бернардо Провенцано был схвачен на Сицилии отчасти из-за того, что некоторые из его сообщений, неуклюже написанных с использованием шифра Цезаря, были взломаны. В шифре Провенцано использовались числа, так что «A» записывалось как «4», «B» как «5» и так далее.
В 2011 году Раджиб Карим был осужден в Соединенном Королевстве за «террористические преступления» после того, как использовал шифр Цезаря для общения с бангладешскими исламскими активистами, обсуждая заговоры с целью взорвать самолеты British Airways или нарушить работу их ИТ-сетей. Хотя стороны имели доступ к гораздо более совершенным методам шифрования (сам Карим использовал PGP для хранения данных на дисках компьютеров), они решили использовать свою собственную схему (реализованную в Microsoft Excel ), отказавшись от более сложной программы кода под названием «Секреты моджахедов», «потому что кафры «или неверующие знают об этом, поэтому он должен быть менее безопасным». Это представляло собой применение безопасности через безвестность .
Моноалфавитная замена
Описанные выше ROTN и азбука Морзе являются представителями шрифтов моноалфавитной замены. Приставка «моно» означает, что при шифровании каждая буква изначального сообщения заменяется другой буквой или кодом из единственного алфавита шифрования.
Дешифрование шифров простой замены не составляет труда, и в этом их главный недостаток. Разгадываются они простым перебором или частотным анализом. Например, известно, что самые используемые буквы русского языка — это «о», «а», «и». Таким образом, можно предположить, что в зашифрованном тексте буквы, которые встречаются чаще всего, означают либо «о», либо «а», либо «и». Исходя из таких соображений, послание можно расшифровать даже без перебора компьютером.
Известно, что Мария I, королева Шотландии с 1561 по 1567 г., использовала очень сложный шифр моноалфавитной замены с несколькими комбинациями. И все же ее враги смогли расшифровать послания, и информации хватило, чтобы приговорить королеву к смерти.
ROT1 и шифр Цезаря
Название этого шифра ROTate 1 letter forward, и он известен многим школьникам. Он представляет собой шифр простой замены. Его суть заключается в том, что каждая буква шифруется путем смещения по алфавиту на 1 букву вперед. А -> Б, Б -> В, …, Я -> А. Например, зашифруем фразу «наша Настя громко плачет» и получим «общб Обтуа дспнлп рмбшеу».
Шифр ROT1 может быть обобщен на произвольное число смещений, тогда он называется ROTN, где N — это число, на которое следует смещать шифрование букв. В таком виде шифр известен с глубокой древности и носит название «шифр Цезаря».

Шифр Цезаря очень простой и быстрый, но он является шифром простой одинарной перестановки и поэтому легко взламывается. Имея подобный недостаток, он подходит только для детских шалостей.
Шифр Цезаря
Итак, после небольшого введения в цикл, я предлагаю все-таки перейти к основной теме сегодняшней статьи, а именно к Шифру Цезаря.
Что это такое?
Шифр Цезаря — это простой тип подстановочного шифра, где каждая буква обычного текста заменяется буквой с фиксированным числом позиций вниз по алфавиту. Принцип его действия можно увидеть в следующей иллюстрации:
Какими особенностями он обладает?
У Шифра Цезаря, как у алгоритма шифрования, я могу выделить две основные особенности. Первая особенность — это простота и доступность метода шифрования, который, возможно поможет вам погрузится в эту тему, вторая особенность — это, собственно говоря, сам метод шифрования.
Программная реализация
В интернете существует огромное множество уроков, связанных с криптографией в питоне, однако, я написал максимально простой и интуитивно понятный код, структуру которого я вам продемонстрирую.
Начнем, пожалуй, с создания алфавита. Для этого вы можете скопировать приведенную ниже строку или написать все руками.
Далее, нам нужно обозначить программе шаг, то есть смещение при шифровании. Так, например, если мы напишем букву «а» в сообщении, тот при шаге «2», программа выведет нам букву «в».
Итак, создаем переменнуюsmeshenie, которая будет вручную задаваться пользователем, и message, куда будет помещаться наше сообщение, и, с помощью метода возводим все символы в нашем сообщении в верхний регистр, чтобы у нас не было ошибок. Потом создаем просто пустую переменную itog, куда мы буем выводить зашифрованное сообщение. Для этого пишем следующее:
Итак, теперь переходим к самому алгоритму шифровки. Первым делом создаем цикл, где мы определим место букв, задействованных в сообщении, в нашем списке alfavit, после чего определяем их новые места (далее я постараюсь насытить код с пояснениями):
Далее, мы создаем внутри нашего цикла условие , в нем мы записываем в список itog мы записываем наше сообщение уже в зашифрованном виде и выводим его:
Модернизация
Вот мы и написали программу, однако она имеет очень большой недостаток: «При использовании последних букв(русских), программа выведет вам английские буквы. Давайте это исправим.
Для начала создадим переменную lang, в которой будем задавать язык нашего шифра, а так же разделим английский и русский алфавиты.
Теперь нам надо создать условие, которое проверит выбранный язык и применит его, то есть обратится к нужному нам алфавиту. Для этого пишем само условие и добавляем алгоритм шифрования, с помощью которого будет выполнено шифрование:
Дешифровка сообщения
Возможно это прозвучит несколько смешно, но мы смогли только зашифровать сообщение, а насчет его дешифровки мы особо не задумывались, но теперь дело дошло и до неё.
По сути, дешифровка — это алгоритм обратный шифровке. Давайте немного переделаем наш код (итоговый вид вы можете увидеть выше).
Для начала, я предлагаю сделать «косметическую» часть нашей переделки. Для этого перемещаемся в самое начало кода:
Остальное можно оставить так же, но если у вас есть желание, то можете поменять названия переменных.
По большому счету, самые ‘большие’ изменения у нас произойдут в той части кода, где у нас находится алгоритм, где нам нужно просто поменять знак «+» на знак «-«. Итак, переходим к самому циклу:
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
-
Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.. Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
Почему шифрование слабое?
Как бы ни был прост в понимании и применении шифр Цезаря, он облегчает любому взлом дешифровки без особых усилий.
Шифр Цезаря – это метод подстановочного шифрования, при котором мы заменяем каждый символ в тексте некоторым фиксированным символом.
Если кто-то обнаружит регулярность и закономерность появления определенных символов в шифротексте, он быстро определит, что для шифрования текста был использован шифр Цезаря.
Если убедиться, что для шифрования текста использовалась техника шифра Цезаря, то восстановить оригинальный текст без ключа будет проще простого.
Простой алгоритм Brute Force вычисляет оригинальный текст за ограниченное время.
Атака методом перебора
Взлом шифротекста с помощью шифра Цезаря – это просто перебор всех возможных ключей.
Это осуществимо, потому что может существовать только ограниченное количество ключей, способных генерировать уникальный шифротекст.
Например, если в шифротексте зашифрованы все строчные буквы, то все, что нам нужно сделать, это запустить шаг расшифровки со значениями ключа от 0 до 25.
Даже если бы пользователь предоставил ключ выше 25, он выдал бы шифротекст, равный одному из шифротекстов, сгенерированных с ключами от 0 до 25.
Давайте рассмотрим шифротекст, в котором зашифрованы все строчные символы, и посмотрим, сможем ли мы извлечь из него разумный шифротекст с помощью атаки “методом перебора”.
У нас есть текст:
Сначала определим функцию расшифровки, которая принимает шифротекст и ключ и расшифровывает все его строчные буквы.
Теперь у нас есть наш текст, но мы не знаем ключа, т.е. значения смещения. Давайте напишем атаку методом перебора, которая пробует все ключи от 0 до 25 и выводит каждую из расшифрованных строк:
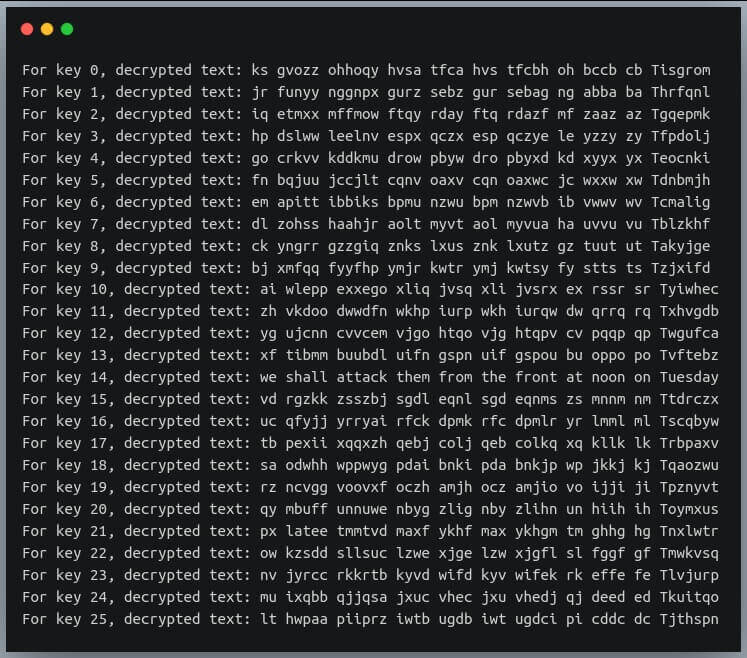
В выводе перечислены все строки, которые могут быть получены в результате расшифровки.
Если вы внимательно посмотрите, строка с ключом 14 является правильным английским высказыванием и поэтому является правильным выбором.

Теперь вы знаете, как взломать шифр с помощью шифра Цезаря.
Мы могли бы использовать другие более сильные варианты шифра Цезаря, например, с использованием нескольких сдвигов (шифр Виженера), но даже в этих случаях определенные злоумышленники могут легко расшифровать правильную расшифровку.
Поэтому алгоритм шифрования Цезаря относительно слабее современных алгоритмов шифрования.
Стеганография
Стеганография старше кодирования и шифрования. Это искусство появилось очень давно. Оно буквально означает «скрытое письмо» или «тайнопись». Хоть стеганография не совсем соответствует определениям кода или шифра, но она предназначена для сокрытия информации от чужих глаз.

Стеганография является простейшим шифром. Типичными ее примерами являются проглоченные записки, покрытые ваксой, или сообщение на бритой голове, которое скрывается под выросшими волосами. Ярчайшим примером стеганографии является способ, описанный во множестве английских (и не только) детективных книг, когда сообщения передаются через газету, где малозаметным образом помечены буквы.
Главным минусом стеганографии является то, что внимательный посторонний человек может ее заметить. Поэтому, чтобы секретное послание не было легко читаемым, совместно со стеганографией используются методы шифрования и кодирования.
Решение
Теперь, когда мы определили наши две функции, давайте сначала воспользуемся функцией шифрования, чтобы зашифровать секретное сообщение, которое друг передает через текстовое сообщение своему другу.
Обратите внимание, что все, кроме знаков препинания и пробелов, зашифровано. Теперь давайте посмотрим на шифрованный текст, который полковник Ник Фьюри посылал на свой пейджер: “Mr xli gsyrx sj 7, 6, 5 – Ezirkivw Ewwiqfpi!”
Теперь давайте посмотрим на шифрованный текст, который полковник Ник Фьюри посылал на свой пейджер: “Mr xli gsyrx sj 7, 6, 5 – Ezirkivw Ewwiqfpi!”.
Это оказывается шифротекст Цезаря, и, к счастью, ключ к этому шифру у нас в руках.
Давайте посмотрим, сможем ли мы обнаружить скрытое послание.
Отличная работа, Мстители!
Линейный криптоанализ
Еще один метод взлома блочных шифров — линейный криптоанализ. Он является одним из самых распространенных подходов. Анализ основывается на построении соотношений между открытым текстом P, ключом K и зашифрованным сообщением C, а затем их использовании для нахождения ключа.
Соотношения в алгоритме — это уравнения следующего вида:
Вероятность выполнения этого соотношения для произвольно выбранных битов примерно равна 0.5. Цель линейного криптоанализа — найти такие наборы битов, что эта вероятность сильно отличается от 0.5 в одну или другую сторону. Вероятности подсчитываются путем полного перебора всех возможных значений входов для S-блока.
Ключ находится следующим образом:
Для каждого возможного набора битов ключа проверяется, на скольких парах текст-шифротекст выполняется найденное соотношением. Выбирается тот набор битов, для которого отклонение числа пар от половины всех пар наибольшее.
Линейный криптоанализ оказался очень мощным инструментом и может применять не только к блочным, но и к потоковым шифрам.
Шифр Вернама — это сложно
Теперь попробуем объяснить подробнее.
1. Сообщение хранится в виде битов данных. Допустим, мы шифруем текст. Компьютер не умеет работать с текстом как таковым, он этот текст хранит как набор числовых кодов (проще говоря, у компьютера все буквы пронумерованы и он помнит только эти номера).
Числа, в свою очередь, компьютер хранит в виде двоичного кода, то есть битов данных. Это пока что не относится к шифрованию, это просто то, как хранится любая текстовая информация в компьютере.
| Буква | Код в ASCII | Биты данных |
| K | 75 | 01001011 |
| O | 79 | 01001111 |
| D | 68 | 01000100 |
Если мы напишем KOD в кодировке ASCII, то для компьютера это будет последовательность из трёх чисел, а каждое число — это набор битов:
01001011 01001111 01000100
2. Берём случайные биты в качестве ключа шифрования. На входе у нас три числа по 8 бит. Чтобы их зашифровать, нам нужны 24 случайных бита. Возьмём их с потолка, они ничего не значат:
10101101 01111010 10101011
3. Накладываем коды друг на друга и применяем алгоритм шифрования. Шифр Вернама построен на принципе «исключающего ИЛИ», он же XOR. Он смотрит на каждую пару битов и пытается понять, они одинаковые или разные. Если биты одинаковые, результат проверки будет 0, если разные — 1.
Можно проверить себя так: XOR задаёт вопрос «Эти биты разные»? Если да — то 1, если нет — то 0.
| Буква K | 1 | 1 | 1 | 1 | |
| Ключ | 1 | 1 | 1 | 1 | 1 |
| XOR (Они разные?) | 1 | 1 | 1 | 1 | 1 |
Если мы таким образом закодируем три буквы, мы получим три новых набора битов:
| KOD (сообщение) | 01001011 | 01001111 | 01000100 |
| Ключ | 10101101 | 01111010 | 10101011 |
| Результат шифрования с помощью XOR | 11100110 | 00110101 | 11101111 |
Получается, что на входе у нас было 24 бита данных и на выходе 24 бита данных. Но эти данные теперь совсем другие. Если перевести эти числа обратно в текст, мы получим:
KOD → æ5ï
Функция chr()
Точно так же, как при преобразовании символа в его числовой Юникод с помощью метода ord(), мы делаем обратное, то есть находим символ, представленный числом, с помощью метода chr().
Метод chr() принимает число, представляющее Unicode символа, и возвращает фактический символ, соответствующий числовому коду.
Давайте сначала рассмотрим несколько примеров:
Обратите внимание, что немецкая буква Ü также представлена в Юникоде числом 360. Мы можем применить процедуру цепочки (ord, затем chr), чтобы восстановить исходный символ
Мы можем применить процедуру цепочки (ord, затем chr), чтобы восстановить исходный символ.
Расшифровка шифра Вернама
Если у нас есть закодированное сообщение и ключ от него, то раскодировать его не составит труда. Мы просто пишем алгоритм, который применяет операцию XOR как бы в обратном порядке к каждому биту сообщения. Например:
- Если в ключе шифрования в каком-то бите стоит 1, то мы берём этот же бит в зашифрованном сообщении и меняем его. Если был 1, то меняем на 0. Если был 0, то меняем на 1.
- Если в ключе шифрования в каком-то бите стоит 0, то этот же бит в зашифрованном сообщении мы не меняем.
- Проходим так по каждому биту сообщения и получаем исходный текст.
Компьютер может совершать миллиарды таких операций в секунду. Главное — иметь на руках ключ для расшифровки.
Концептуальные основы
Пусть будет текстовое сообщение, которое Алиса хочет тайно передать Бобу, и пусть будет шифр шифрования, где — криптографический ключ . Алиса должна сначала преобразовать открытый текст в зашифрованный , чтобы безопасно отправить сообщение Бобу, как показано ниже:
м{\ Displaystyle м \!}Ek{\ displaystyle E_ {k} \!}k{\ displaystyle _ {k} \!}c{\ displaystyle c \!}
- cзнак равноEk(м).{\ displaystyle c = E_ {k} (м). \!}
В системе с симметричным ключом Боб знает ключ шифрования Алисы. После того, как сообщение зашифровано, Алиса может безопасно передать его Бобу (при условии, что никто другой не знает ключ). Чтобы прочитать сообщение Алисы, Боб должен расшифровать зашифрованный текст, используя который известен как шифр дешифрования,Ek-1{\ displaystyle {E_ {k}} ^ {- 1} \!}Dk{\ displaystyle D_ {k}: \!}
- Dk(c)знак равноDk(Ek(м))знак равном.{\ Displaystyle D_ {к} (с) = D_ {k} (E_ {k} (м)) = м. \!}
В качестве альтернативы, в системе с несимметричным ключом все, а не только Алиса и Боб, знают ключ шифрования; но ключ дешифрования не может быть выведен из ключа шифрования. Только Боб знает ключ дешифрования, и дешифрование происходит как
Dk,{\ displaystyle D_ {k},}
- Dk(c)знак равном.{\ Displaystyle D_ {k} (с) = м.}
Азбука Морзе
Азбука является средством обмена информации и ее основная задача — сделать сообщения более простыми и понятными для передачи. Хотя это противоречит тому, для чего предназначено шифрование. Тем не менее она работает подобно простейшим шифрам. В системе Морзе каждая буква, цифра и знак препинания имеют свой код, составленный из группы тире и точек. При передаче сообщения с помощью телеграфа тире и точки означают длинные и короткие сигналы.

Телеграф и азбука Морзе… Морзе был тем, кто первый запатентовал «свое» изобретение в 1840 году, хотя до него и в России, и в Англии были изобретены подобные аппараты. Но кого это теперь интересует… Телеграф и азбука Морзе оказали очень большое влияние на мир, позволив почти мгновенно передавать сообщения на континентальные расстояния.
Концептуальные основы [ править ]
Пусть будет текстовое сообщение, которое Алиса хочет тайно передать Бобу, и пусть будет шифром, где — криптографический ключ . Алиса должна сначала преобразовать открытый текст в зашифрованный , чтобы безопасно отправить сообщение Бобу, как показано ниже:
м{\ Displaystyle м \!}Ek{\ displaystyle E_ {k} \!}k{\ displaystyle _ {k} \!}c{\ displaystyle c \!}
- cзнак равноEk(м).{\ displaystyle c = E_ {k} (м). \!}
В системе с симметричным ключом Боб знает ключ шифрования Алисы. После того, как сообщение зашифровано, Алиса может безопасно передать его Бобу (при условии, что никто другой не знает ключ). Чтобы прочитать сообщение Алисы, Боб должен расшифровать зашифрованный текст, используя который известен как шифр дешифрования,Ek-1{\ displaystyle {E_ {k}} ^ {- 1} \!}Dk{\ displaystyle D_ {k}: \!}
- Dk(c)знак равноDk(Ek(м))знак равном.{\ Displaystyle D_ {к} (с) = D_ {k} (E_ {k} (м)) = м. \!}
В качестве альтернативы, в системе с несимметричным ключом все, а не только Алиса и Боб, знают ключ шифрования; но ключ дешифрования не может быть выведен из ключа шифрования. Только Боб знает ключ дешифрования, и дешифрование происходит как
Dk,{\ displaystyle D_ {k},}
- Dk(c)знак равном.{\ Displaystyle D_ {k} (с) = м.}
Дальнейшее чтение [ править ]
- Хелен Фуше Гейнс, «Криптоанализ», 1939, Дувр. ISBN 0-486-20097-3
- Дэвид Кан , Взломщики кодов — История секретного письма ( ISBN 0-684-83130-9 ) (1967)
- Абрахам Синьков , Элементарный криптоанализ: математический подход , Математическая ассоциация Америки, 1968. ISBN 0-88385-622-0
|
Частотный анализ
Простые шифры
Частотный анализ использует гипотезу о том, что символы или последовательности символов в тексте имеют некоторое вероятностное распределение, которое сохраняется при шифровании и дешифровании.
Этот метод один из самых простых и позволяет атаковать шифры простой замены, в которых символы в сообщении заменяются на другие согласно некоторому простому правилу соответствия.
Однако такой метод совершенно не работает, например, на шифрах перестановки. В них буквы или последовательности в сообщении просто меняются местами, но их количество всегда остается постоянным, как в анаграммах, поэтому ломаются все методы, основанные на вычислении частот появления символов.
Для полиалфавитных шифров — шифров, в которых циклически применяются простые шифры замены — подсчет символов так же не будет эффективен, поскольку для кодировки каждого символа используется разный алфавит. Число алфавитов и их распределение так же неизвестно.
Шифр Виженера
Один из наиболее известных примеров полиалфавитных шифров — шифр Виженера. Он довольно прост в понимании и построении, однако после его создания еще 300 лет не находилось способа взлома этого шифра.
Пусть исходный текст это: МИНДАЛЬВАНГОГ
-
Составляется таблица шифров Цезаря по числу букв в используемом алфавите. Так, в русском алфавите 33 буквы. Значит, таблица Виженера (квадрат Виженера) будет размером 33х33, каждая i-ая строчка в ней будет представлять собой алфавит, смещенный на i символов.
-
Выбирается ключевое слово. Например, МАСЛО. Символы в ключевом слове повторяются, пока длина не достигнет длины шифруемого текста: МАСЛОМАСЛОМАС.
-
Символы зашифрованного текста определяются по квадрату Виженера: столбец соответствует символу в исходном тексте, а строка — символу в ключе. Зашифрованное сообщение: ЩЙЯРПШЭФМЬРПХ.

Этот шифр действительно труднее взломать, однако выделяющиеся особенности у него все же есть. На выходе все же не получается добиться равномерного распределения символов (чего хотелось бы в идеале), а значит потенциальный злоумышленник может найти взаимосвязь между зашифрованным сообщением и ключом. Главная проблема в шифре Виженера — это повторение ключа.
Взлом этого шифра разбивается на два этапа:
-
Поиск длины ключа. Постепенно берутся различные образцы из текста: сначала сам текст, потом текст из каждой второй буквы, потом из каждой третьей и так далее. В некоторый момент можно будет отвергнуть гипотезу о равномерном распределении букв в таком тексте — тогда длина ключа считается найденной.
-
Взлом нескольких шифров Цезаря, которые уже легко взламываются.
Поиск длины ключа — самая нетривиальная здесь часть. Введем индекс совпадений сообщения m:
где n — количество символов в алфавите и
p_i — частота появления i-го символа в сообщении. Эмпирически были найдены индексы совпадений для текстов на разных языков. Оказывается, что индекс совпадений для абсолютно случайного текста гораздо ниже, чем для осмысленного текста. С помощью этой эвристики и находится длина ключа.
Другой вариант — применить критерий хи-квадрат для проверки гипотезы о распределении букв в сообщении. Тексты, получаемые выкидыванием некоторых символов, все равно остаются выборкой из соответствующего распределения. Тогда в критерии хи-квадрат вероятности появления символов можно выбрать используя частотные таблицы языка.